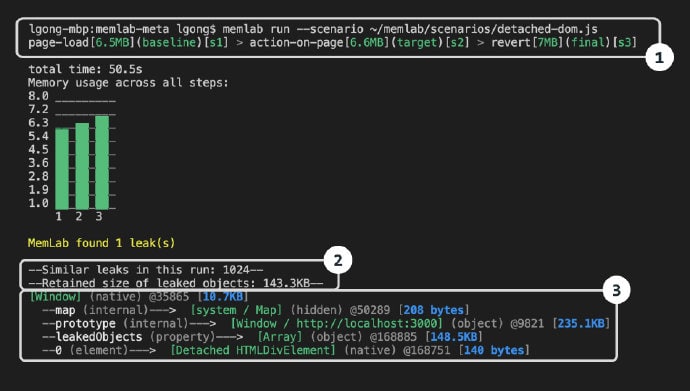
一个在 Kubernetes 上运行的弹性网络抓取集群。它提供了通过 REST API 和 Web 界面部署、运行和扩展 Web 抓取蜘蛛的机制。
该项目由三个主要模块组成:
REST API:使用 Django REST 框架工具包构建,它公开了几个端点来管理项目、蜘蛛和作业。它使用 Celery 进行任务处理,并负责部署 Scrapy 项目等。
排队:estela 需要一个高吞吐量、低延迟的平台来控制生产者-消费者架构中的实时数据馈送。在本模块中,您将找到一个 Kafka 消费者,用于收集蜘蛛作业中的信息并将其传输到数据库中。
Web:使用 React 和 Typescript 实现的 Web 界面,可让您管理项目和蜘蛛。
这些模块中的每一个都独立于其余模块工作,并且可以更改。每个模块在其对应的目录中都有更详细的描述。
estela